Distribution of Speech & Silence Durations (1)
1. Speech and silence in political speeches
If you look at the .word file resulting from our earlier forced-alignment exercise on the passage from one of president Obama's weekly addresses, you'll see that it starts like this:
0.0125 0.0225 sp
0.0225 0.1125 A
0.1125 0.3725 year
0.3725 0.8225 ago
0.8225 1.0325 sp
1.0325 1.1725 when
1.1725 1.2625 I
1.2625 1.4925 took
1.4925 1.9325 office
and ends like this:
330.3925 330.8325 nation
330.8325 331.4025 sp
331.4025 331.5825 and
331.5825 331.7425 one
331.7425 332.0625 people
332.0625 332.9725 sp
332.9725 333.2025 Thanks
333.2025 333.3125 for
333.3125 333.6425 listening
333.6425 334.3625 sp
where the pair of numbers at the start of each line indicates the starttime and endtime of the corresponding alignment, and "sp" is the name used for silence.
So we can write a trivial program to add up the silence times (ignoring the start and end silences) and the speech times, and we'll learn that the recording has 274.84 seconds of speech, and 58.78 seconds of silence, for a speech-to-silence ratio of 4.68, or a "duty factor" of 274.84/(274.84+58.78) = 0.824.
A slightly less trivial program will let us merge adjacent speech segments, and determine that the mean speech segment duration is 1.88 seconds, while the mean silence duration is 0.41 seconds. And we can easily generate histograms like those below, or calculate other things like quantiles or conditional distributions:


(We'll learn later how to write simple programs of this type.)
It should be obvious that the same person might have very different distributions of speech and silence durations on different occasions, for a wide variety of reasons. And even in exactly the same context, different people will differ: for an example, see "The rhetoric of silence" 10/3/2004.
Although the sequence of speech and silence durations is a crude measure, it offers significant information about the process of speech planning and execution, and may have diagnostic value in some clinical applications.
2. Speech and silence in Cookie Theft recordings
In particular, there's good reason to think that this is a plausible way to begin addressing the issues discussed in Sherry Ash's readings on the phonetic of neurodegenerative diseases and in Naomi Nevler's presentation "Dysfluency and Dysprosody in FrontoTemporal Degeneration".
But here we will be dealing with speech that may be quite disfluent, and with recordings of variable quality, and with transcripts that are not always complete, or may include human-readable "notes to self" that may confuse a forced-alignment program. So we'll start by learning to create efficient phrase-aligned transcripts, and then in a second step, we'll compare the results from various sorts of automatic or semi-automatic processing, including a "speech activity detector" (SAD) that doesn't require a transcript.
A sample of 16 "Cookie Theft" narratives can be found in harris.sas.upenn.edu:/plab/L521/Cookie. There are 16 .wav files (Cookie1.wav to Cookie16.wav) and 16 .txt files (Cookie1.txt to Cookie16.txt).
I suggest using the Transcriber program to do the transcriptions. In class you'll be shown how to install the program and how to use it for this particular application. Step-by-step instructions are below -- if you run into problems, ask for help on the class Piazza site.
A. Make your own copy of the data: Use scp -r (or ws_ftp or fetch) to copy the directory harris.ldc.upenn.edu:/plab/L521/Cookie to your own machine.
B. Install the Transcriber program: You should be able to find a working version at http://sourceforge.net/projects/trans/
Once you've installed it, read the User Guide (menu Help>>User Guide) and perhaps the other documentation.
C: Open Cookie1.wav in Transcriber: This should be self-explanatory.
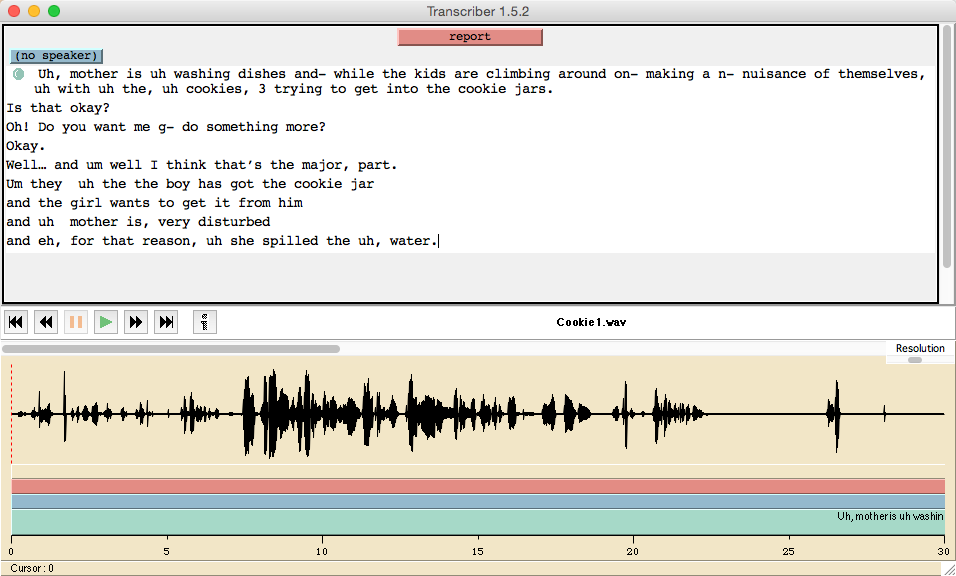
D: Cut and paste the transcription from Cookie1.txt into the upper Transcriber window: One easy way to do this is (in a terminal window) to cd to the correct directory, cat the file, select the text with the mouse, and use control-C (or command-C) to snarf the text, and then control-V (or command-V) to paste it into Transcriber:

Alternatively you could read Cookie1.txt into a plain text editor, and do the same snarfing-and-pasting. You should now have something that looks like this (issues of window size and font size aside):
E. Completing the Alignment: Change the time resolution of the waveform window (the lower panel) to 10 seconds (via menu Signal>>Resolution>10 seconds), which is a convenient compromise letting you see several phrases at once, while still positioning the cursor at a chosen time accurately enough.
Use the tab key to start and stop playing until you get to the beginning of the transcribed portion. Now
- In the lower (waveform) window, use the mouse to position the (vertical red) cursor just before the start of the sound of the first transcribed word;
- In the upper (text) window, use the mouse to position the (vertical black) cursor just before the first letter of the first transcribed word;
- Hit ENTER on the keyboard.
This will establish corresponding break points in the audio and text windows. Now, leaving the text cursor at the start of the first transcribed word, use command-T (or control-T) to create a speaker turn for a speaker labelled "Subject". Now thing should look like this:
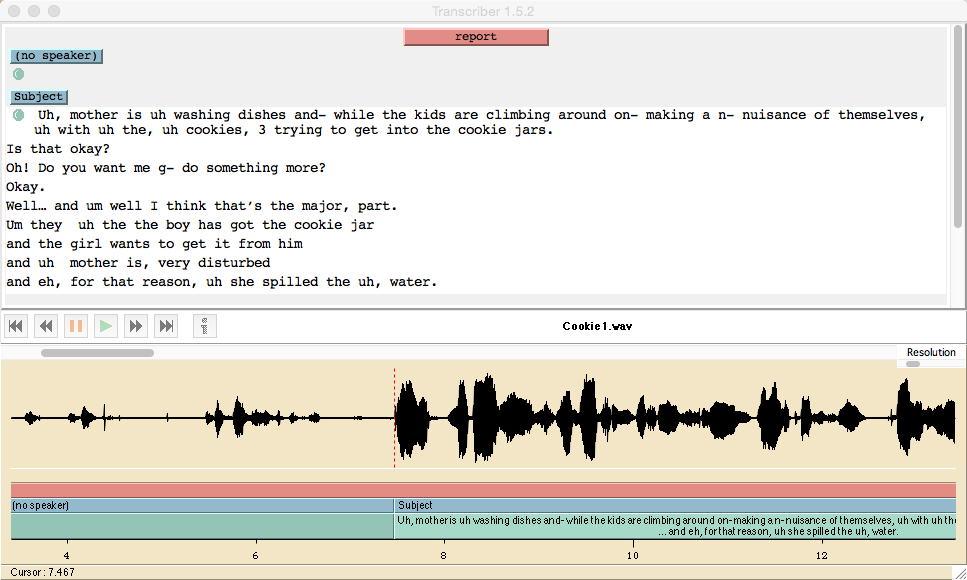
Now go on to establish break points (using ENTER) at all significant silences. Do not establish new speaker turns unless the speaker changes -- but if the interviewer intervenes, create a turn whose speaker is labelled "Interviewer". And if the interviewer intervenes, label the silence between the subject and the interviewer with a pseudo-speaker ID "S2I", and the silence between the interviewer and the subject with a pseudo-speaker ID "I2S".
You will note that there may be some special spellings and "notes to self" in the transcript text, including multiplied letters to indicated elongation of words (e.g. "uuuuuh"), numbers estimating silence durations, phonemic or phonetic transcriptions, etc. Remove all of these.
If any speech is omitted, or if you think the transcript is wrong, correct it.
Note these features of the Transcriber program:
- You can use the mouse to select a region of the waveform to play;
- You can zoom to the selection -- and unzoom back to where you were -- using the menu (e.g. Signal>>Zoom Selection) or the keyboard shortcuts option-Z and option-U (or alt-Z and alt-U on Windows);
- You can adjust the location of a breakpoint in the waveform window with control-click and drag.
Other useful features are documented in the Help files.
On some operating system versions, attempting to snarf a region of text from the upper text window may cause the program to crash -- in general, you should be sure to save your transcription (as Cookie1.trs, in the same directory) frequently, to avoid losing your work.
Once you've learned to use the program, doing the alignment and correction for one Cookie Theft file should take no more than 5 to 10 minutes. If it takes more time than that, you're Doing It Wrong and should ask for help.
F: Fixing audio levels: Some of the Cookie Theft descriptions were REALLY badly recorded. In particular, Cookie4, Cookie8, Cookie12, and Cookie 16 have such low sound levels that you probably may not even be able to hear the speech, and certainly won't be able to visually find the edges of utterances.
The best way to fix this is to download and install the free audio editor Audacity. Then open a problematic file in Audacity, and use Effects>>Normalize or Effects>>Amplify (and you may need both effects, because some of the files also have a DC offset, which Normalize can remove, while other files may have one or two very loud clicks along with general audio levels a few thousand times smaller, so that Normalize -- which avoids clipping -- may not amplify nearly enough in such cases). Once you have a version of the file that looks and sounds OK, save it as (e.g.) Cookie4a.wav, and go on as before.
I haven't fixed these for you in advance for two reasons: (1) It's useful to learn how to deal with crappy recordings; (2) It's useful to learn why it's a good idea to check the levels when you make a recording.
You should get your transcriptions done and uploaded to the Canvas site by 2/10/2016.