Checking allophonic variation in voiceless stops
Goal:
- Learn to use forced alignment on large audio recordings to quickly scan relevant sections, and examine/categorize/measure them.
Once we know what we're doing, this approach lets us produce categorizations and measurements at rates from 200 to 1,000 per hour, meaning that the empirical basis for a large-scale phonetics experiment can in principle be accomplished in half a day -- once we have the recordings, the orthographic transcripts, and a well-defined set of questions to ask.
You should get this done by 2/3/2016 -- please upload a summary of your experiences to the Canvas site. (I don't need to see all of the details.)
Part 1: Looking at examples, adjusting boundaries, making notes...
1. In harris.sas.upenn.edu:/plab/L521 you'll find the files
| (1) | 010910_WeeklyAddress.wav | Barack Obama's weekly radio address for 1/9/2010 |
| (2) | 010910_WeeklyAddress.txt | Textual transcript for (1) |
| (3) | 010910_WeeklyAddress.align | Output from segment.py based on (1) and (2) |
| (4) | 010910_WeeklyAddress.TextGrid | Produced from (3) via align2textgrid |
Copy these files to a suitable directory on your own machine, and verify that they are sensible. (You should already have your own copies, if you've done "Exercise 1: Simple English Forced Alignment".)
2. Take a look through 010910_WeeklyAddress.align to find all the instances of the abstract dictionary-listed phone /T/.
How many are there? We can find out via
$ grep ' T ' 010910_WeeklyAddress.align | wc 242 1023 8349
which tell us that there are 242 of them.
3. The program align2script will produce a praat script that shows them to us one at a time:
$ grep ' T ' 010910_WeeklyAddress.align | align2script 010910_WeeklyAddress script in Script573.praat -- you can add notes to praatnotes573
(where the "573" part will be different each time you invoke the program...)
[Note that align2script lives on jakobson in /usr/local/bin -- so you can invoke it on jakobson in a folder of your own, or run it on your local machine if you copy /usr/local/bin/align2script to a suitable place like ~/bin, or download it from here.]
Now copy Script573.praat and praatnotes573 to the same place on your own machine where you put the earlier files.
4. Start up Praat and read the script Script573.praat. (On a Mac, you do this via
Praat>>Open Praat script...
Then run the script, via the "Run" menu item in the script window.
You should see something like this:
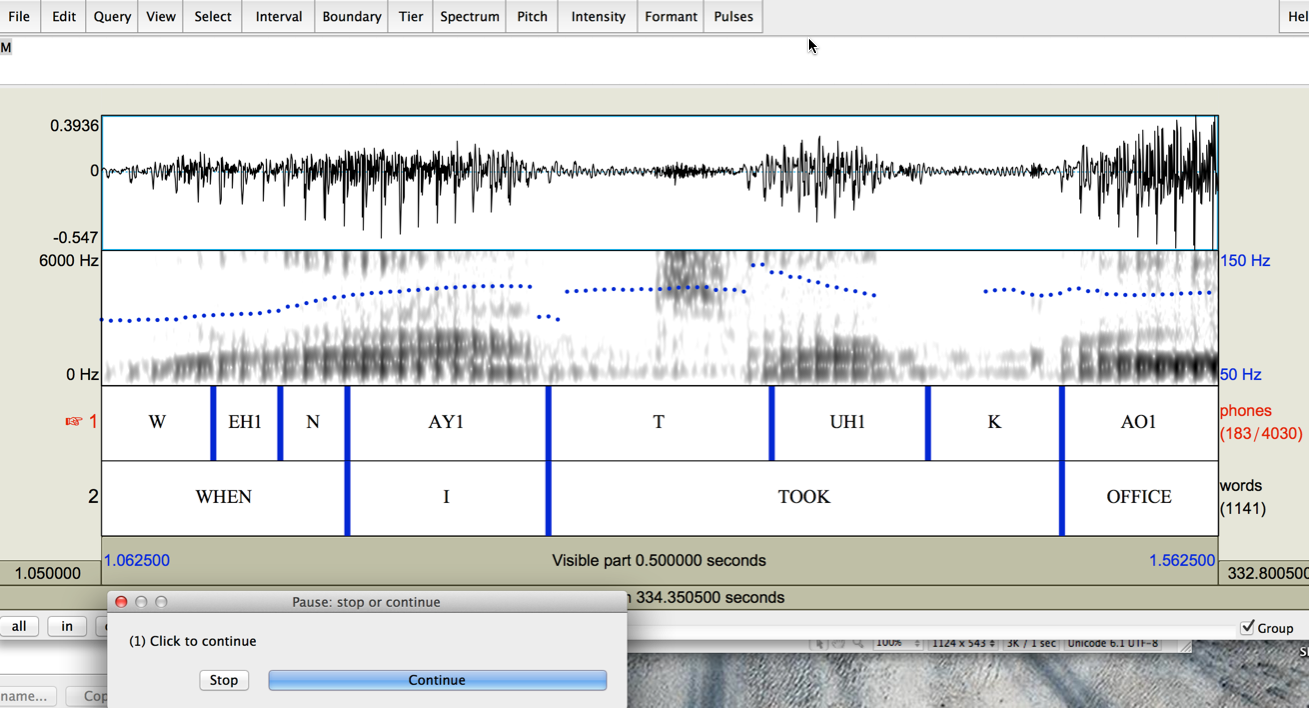
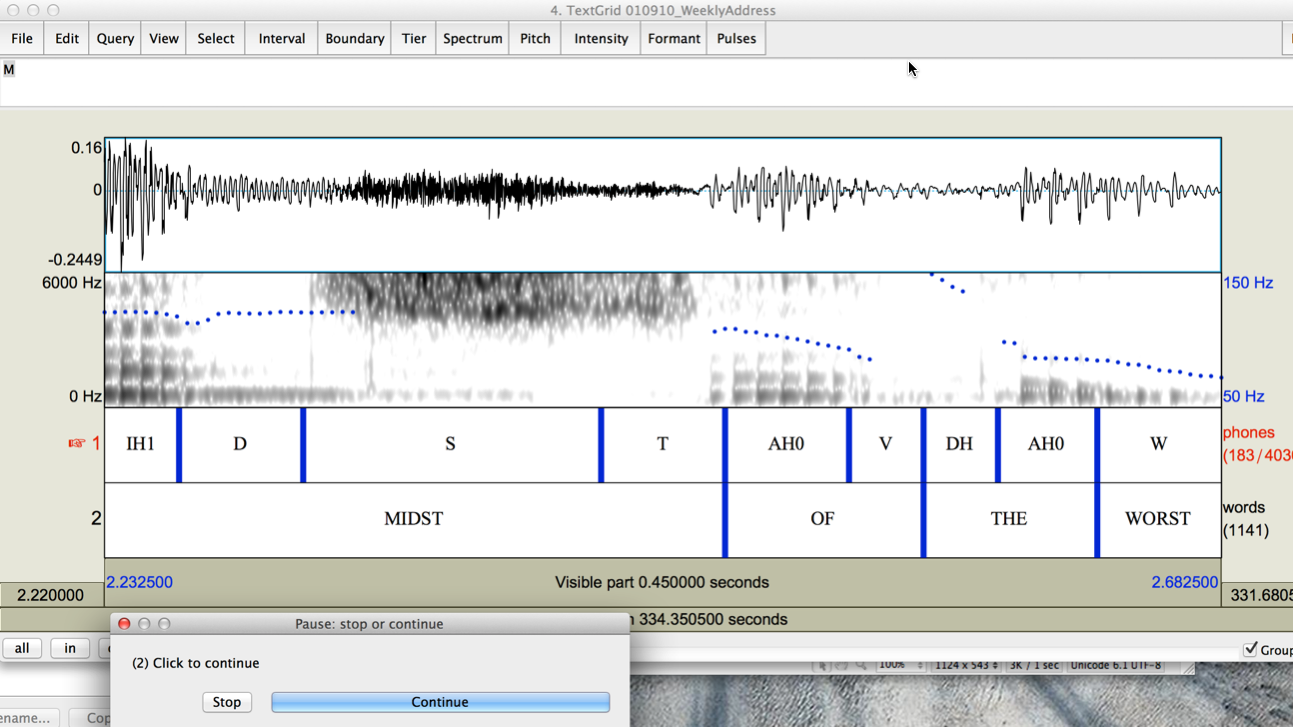
[Note that the "Pause" window now shows "(2)" instead of "(1)".]
If you keep hitting "Continue", you'll eventually cycle through all 242 examples.
Your goal for this first exercise is to look at /T/ examples until you think you've seen everything that Barack Obama has to offer in the way of /T/ allophones.
The aspirated stop (e.g. #1, #6, #11, #12), the final released stop (e.g. #7) and voiced flap (e.g. #9) allophones are pretty easy.
But what should you call #13, which is part of a super reduced form of "that" in the sequence "sometimes bumpy -- that was brought home" (and thus the aligner found it "bumpy" and the silent pause, rather than between the silent pause and "was")? And what is going on in #14 ("brought home")?
The biggest mystery is how to characterize the syllable- or word-final pre-consonantal instances (e.g. #2, #3, #5, #8, etc.). These are the cases that are candidates for "t/d deletion" , which probably should better be called "t/d lenition or maybe deletion or something".
You'll find it convenient to edit the praatnotes573 (or whatever) file to add notes -- it starts out looking like this:
1 1.3125
2 2.4575
3 2.9275
4 3.9225
5 5.3325
...
where each line gives the number of the instance and the center of the aligned location. After your intervention, it might look like:
1 1.3125 "I took" 57ms closure + 42ms aspiration
2 2.4575 "midst of the" 92ms [s] + 57ms [?s?] = weaker [s] as reflex of /t/
3 2.9275 "worst recession" 82ms [s] + no [t]? or maybe weaker [s] before [r]? - [s][?t?][r] sequence is 139ms
4 3.9225 "great depression" /t//d/ sequence has 62ms voiced closure + 18ms aspiration -- pretty much like initial /d/
5 5.3325 "promised you" 48ms [s] 45ms t closure 32ms aspiration
...
Keep it up until you think you see what is going on.
[Note that any time you want to, you can quit the script -- and maybe quit Praat -- and then start it again later, moving through the file to the point where you left off, or creating a new script covering only the examples you haven't processed.]
Part 2: Categorizing Examples
In some cases, rather than checking/adjusting/adding/deleting boundaries, making measurements, or whatever, we want to assign one of a set of labels to each case.
As an example, let's categorize Obama's /t/ segments as "aspirated", "flap", or "other". (This is way too impoverished a set of labels for /t/ allophony in general -- but it serves as an example.)
We start by making a new script file with align2script1:
$ egrep ' T ' 010910_WeeklyAddress.align | align2script1 010910_WeeklyAddress Script19419.praat
(Note again that the numbers between "Script" and ".praat" will be different each time you execute the program...)
When we read that script into Praat and run it, we'll see something like this:
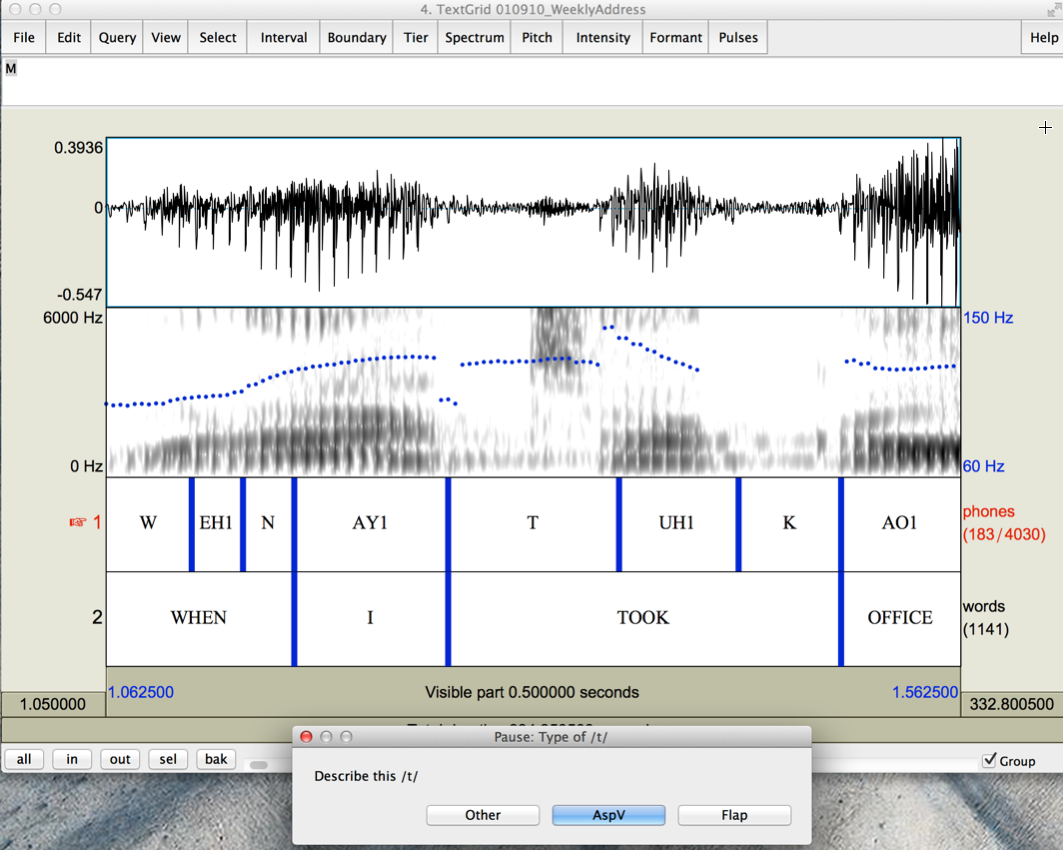
And when we click on the relevant choice, we'll get the next instance:
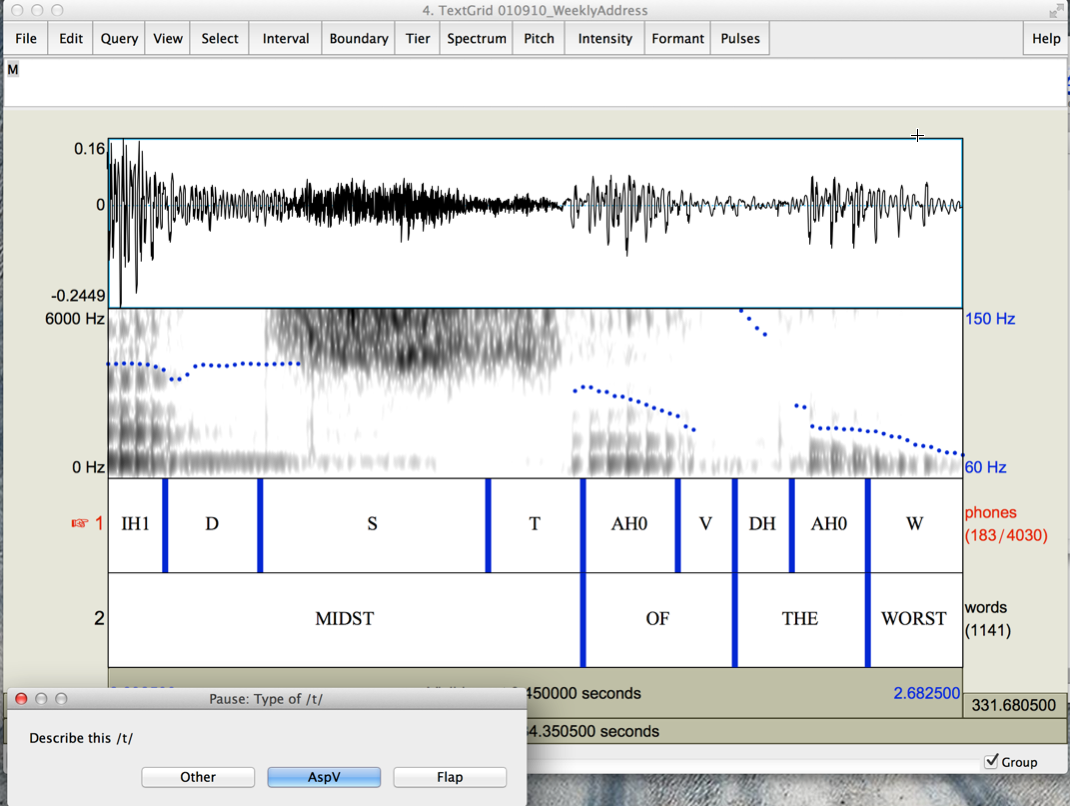
As we go through the list, Praat is writing our judgments out in the file 010910_WeeklyAddress.notes:
# 1=Other 2=Asp+V 3=flap
010910_WeeklyAddress 1.3125 2
010910_WeeklyAddress 2.4575 1
010910_WeeklyAddress 2.9275 1
010910_WeeklyAddress 3.9225 1
010910_WeeklyAddress 5.3325 2
010910_WeeklyAddress 5.4825 2
010910_WeeklyAddress 7.3375 1
010910_WeeklyAddress 7.7775 1
010910_WeeklyAddress 8.3475 3
010910_WeeklyAddress 10.4575 1
010910_WeeklyAddress 10.8625 2
010910_WeeklyAddress 12.7325 2
010910_WeeklyAddress 13.3875 1
010910_WeeklyAddress 14.6575 3